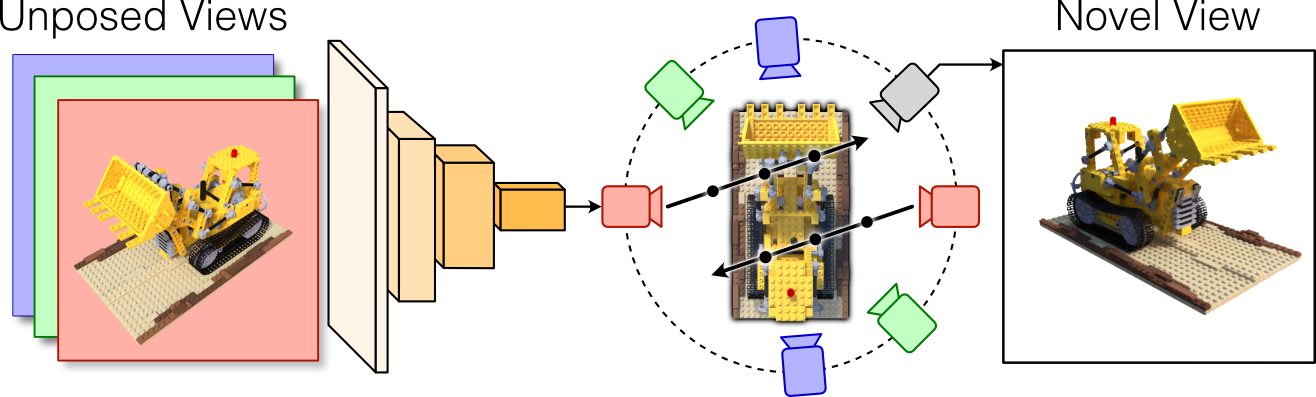
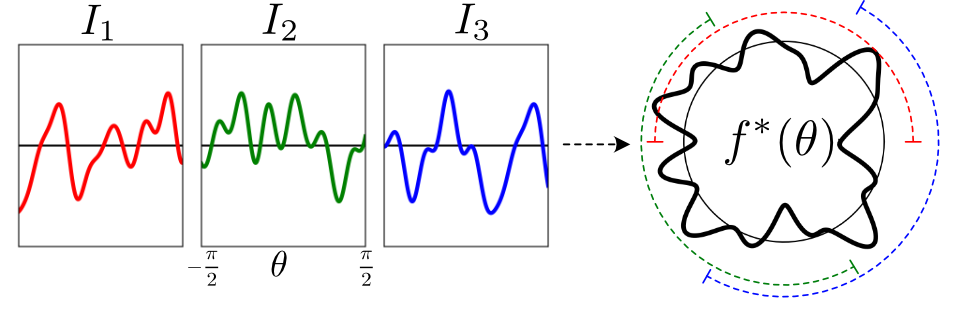
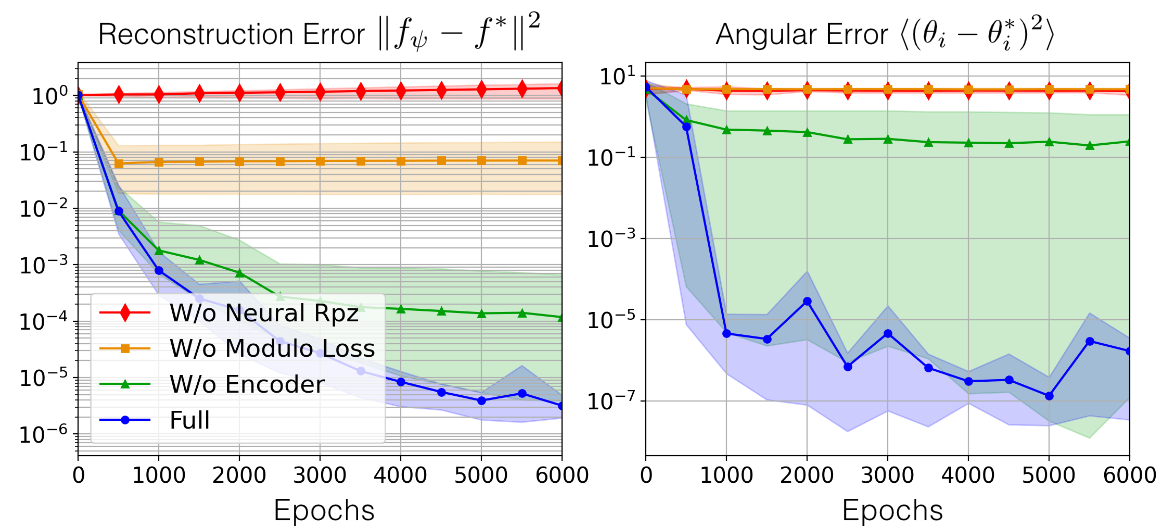
Neural radiance fields enable novel-view synthesis and scene reconstruction with photorealistic quality from a few images, but require known and accurate camera poses. Conventional pose estimation algorithms fail on smooth or self-similar scenes, while methods performing inverse rendering from unposed views require a rough initialization of the camera orientations. The main difficulty of pose estimation lies in real-life objects being almost invariant under certain transformations, making the photometric distance between rendered views non-convex with respect to the camera parameters. Using an equivalence relation that matches the distribution of local minima in camera space, we reduce this space to its quotient set, in which pose estimation becomes a more convex problem. Using a neural-network to regularize pose estimation, we demonstrate that our method - MELON - can reconstruct a neural radiance field from unposed images with state-of-the-art accuracy while requiring ten times fewer views than adversarial approaches.





@article{levy2023melon,
author = {Levy, Axel and Matthews, Mark and Sela, Matan and Wetzstein, Gordon and Lagun, Dmitry},
title = {{MELON}: NeRF with Unposed Images Using Equivalence Class Estimation},
journal = {arXiv:preprint},
year = {2023},
}